BigQuery ML – это способ машинного обучения непосредственно в интерактивном хранилище данных петабайтного масштаба в облаке Google. Вы можете обучать модели машинного обучения миллионам строк за несколько минут, не перемещая данные.
Примечание: BigQuery ML теперь поддерживает извлечение обученной модели в виде TensorFlow SavedModel. Таким образом, вы можете просто экспортировать модель, а затем развернуть ее в Cloud AI Platform Predictions. Тем не менее, эта статья по-прежнему полезна в качестве напоминания о том, как просматривать веса и повторять, что BQML является открытой системой.
Однако, обучив свою модель, вы должны предсказывать с ее помощью. Из коробки BigQuery поддерживает пакетное предсказание — это подходит для приложений отчетности и приборной панели. Однако запросы BigQuery обычно имеют задержку 1-2 секунды, и поэтому возможность пакетного прогнозирования не может быть использована для онлайн-прогнозирования (например, из веб-или мобильного приложения).

В этой статье я покажу вам, как вытащить необходимые веса и параметры масштабирования из таблиц выходных данных обучения и вычислить прогноз самостоятельно. Этот код может быть завернут в структуру веб-приложения или везде, где вы хотите, чтобы код прогнозирования жил.
Полный код этой статьи находится на GitHub.
Создайте модель
Давайте начнем с создания простой модели прогнозирования для прогнозирования задержек прибытия самолетов (подробнее см. Эту статью). Я буду использовать эту модель, чтобы проиллюстрировать процесс.
CREATE OR REPLACE MODEL flights.arrdelay OPTIONS (model_type='linear_reg', input_label_cols=['arr_delay']) AS SELECT arr_delay, carrier, origin, dest, dep_delay, taxi_out, distance FROM `cloud-training-demos.flights.tzcorr` WHERE arr_delay IS NOT NULL
Это заняло у меня около 6 минут, обучило 6 миллионам строк и 267 МБ данных и стоило около $ 1,25. (Бесплатный уровень BigQuery может покрыть это для вас; чтобы снизить стоимость, используйте меньшую таблицу).
Пакетный прогноз с моделью
Как только у вас есть обученная модель, пакетное предсказание можно сделать в самом BigQuery. Например, чтобы найти прогнозируемые задержки прибытия для рейса из DFW в LAX для диапазона задержек вылета, вы можете выполнить этот запрос:
SELECT * FROM ml.PREDICT(MODEL flights.arrdelay, ( SELECT 'AA' as carrier, 'DFW' as origin, 'LAX' as dest, dep_delay, 18 as taxi_out, 1235 as distance FROM UNNEST(GENERATE_ARRAY(-3, 10)) as dep_delay ))
В приведенном выше запросе я жестко кодирую входные значения для carrier, origin и т. Д. И использую функцию GENERATE_ARRAY для генерации задержек вылета в диапазоне от -3 минут до 10 минут. Это дает таблицу с прогнозируемыми задержками прибытия для каждой задержки вылета:
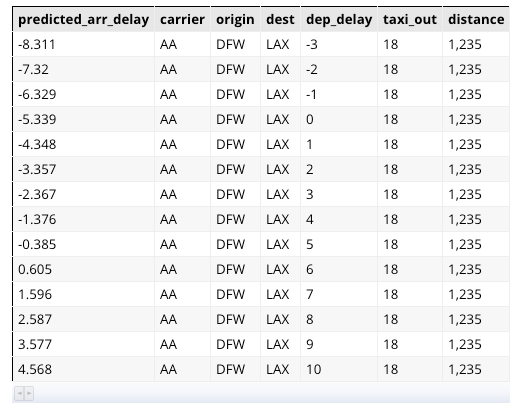
Пакетный прогноз стоит недорого. Приведенный выше запрос обработал 16 КБ и стоил 0,000008 цента.
Хотя этот механизм прогнозирования работает для автономных прогнозов, вы не можете реально использовать его для онлайн-прогнозирования. Если прогнозы должны отображаться в результате взаимодействия с пользователем на веб-сайте или в мобильном приложении, вы не можете позволить себе 1-2-секундную задержку, связанную с каждым вызовом BigQuery. Обычно вам нужны задержки порядка нескольких миллисекунд, и поэтому вам нужно более быстрое решение для вывода.
Веса и масштабирование
К счастью, BigQuery предоставляет всю необходимую информацию для самостоятельного вычисления значения прогноза. Вы можете встроить этот код непосредственно в свое приложение. Я иллюстрирую это на Python, но вы можете сделать это практически на любом языке, который хотите.
Вам нужно вытащить 3 части информации:
- Веса для каждого из ваших числовых столбцов, которые вы можете получить с помощью этого запроса:
SELECT processed_input AS input, model.weight AS input_weight FROM ml.WEIGHTS(MODEL flights.arrdelay) AS model
- Масштабирование для каждого из ваших числовых столбцов, которые вы можете получить с помощью этого запроса:
ВЫSELECT input, min, max, mean, stddev FROM ml.FEATURE_INFO(MODEL flights.arrdelay) AS model
- Словарь и веса для каждого из ваших категориальных столбцов, которые вы можете получить с помощью этого запроса (если вы не знакомы с UNNEST, см. Эту статью).:
SELECT processed_input AS input, model.weight AS input_weight, category.category AS category_name, category.weight AS category_weight FROM ml.WEIGHTS(MODEL flights.arrdelay) AS model, UNNEST(category_weights) AS category
Предполагая, что вы прочитали результаты всех трех этих запросов в трех отдельных фреймов данных Pandas, вот функция, которая вычислит прогноз:
def compute_prediction(rowdict, numeric_weights, scaling_df, categorical_weights):
input_values = rowdict
# numeric inputs
pred = 0
for column_name in numeric_weights['input'].unique():
wt = numeric_weights[ numeric_weights['input'] == column_name ]['input_weight'].values[0]
if column_name != 'INTERCEPT':
meanv = scaling_df[ scaling_df['input'] == column_name ]['mean'].values[0]
stddev = scaling_df[ scaling_df['input'] == column_name ]['stddev'].values[0]
scaled_value = (input_values[column_name] - meanv)/stddev
else:
scaled_value = 1.0
contrib = wt * scaled_value
pred = pred + contrib
# categorical inputs
for column_name in categorical_weights['input'].unique():
category_weights = categorical_weights[ categorical_weights['input'] == column_name ]
wt = category_weights[ category_weights['category_name'] == input_values[column_name] ]['category_weight'].values[0]
pred = pred + wt
return pred
Я делаю следующее:
Прохожу через каждый из числовых столбцов и нахожу вес, связанный с этим столбцом. Затем я вытаскиваю среднее и стандартное отклонение и использую их для масштабирования входного значения. Произведение этих двух величин и есть вклад, связанный с этим столбцом. Затем я прохожу через категориальные столбцы. Для каждого категориального столбца существует отдельный вес, связанный с каждым значением, которое принимает столбец. Итак, я нахожу вес, связанный с входным значением, – это становится вкладом. Сумма всех вкладов – это прогноз.
Приведенный выше код предполагает, что вы обучили регрессионную модель. Если вы обучили модель классификации, вам нужно применить логистическую функцию к прогнозу, чтобы получить вероятность (чтобы избежать переполнения, обработайте вероятность для pred < -500 как ноль):
prob = (1.0/(1 + np.exp(-pred)) if (-500 < pred) else 0)
Вот пример прогнозирования задержки прибытия конкретного рейса:
rowdict = {
'carrier': 'AA',
'origin': 'DFW',
'dest': 'LAX',
'dep_delay': -3,
'taxi_out': 18,
'distance': 1235
}
predicted_arrival_delay = compute_prediction(
rowdict, numeric_weights, scaling_df, categorical_weights)
Это дает следующие столбцы и их вклад:
col = dep_delay wt = 36.5569545237 scaled_value= -0.329782492822 contrib= -12.0558435928
col = taxi_out wt = 8.15557957221 scaled_value = 0.213461991601 contrib = 1.74090625815
col = distance wt = -1.88324519311 scaled_value=0.672196648431 contrib=-1.26591110699
col= __INTERCEPT__ wt = 1.09017737502 scaled_value = 1.0 contrib = 1.09017737502
col=carrier wt=-0.0548843604154 значение =AA contrib= -0.0548843604154
col = origin wt = 0.966535564037 value = DFW contrib = 0.966535564037
col = dest wt = 1.26816262538 value = LAX contrib = 1.26816262538
Общая сумма вкладов составляет -8.31 минуты, что соответствует значению пакетного прогноза, подтверждающему правильность кода.
Полный код этой статьи находится на GitHub. Наслаждайтесь!
