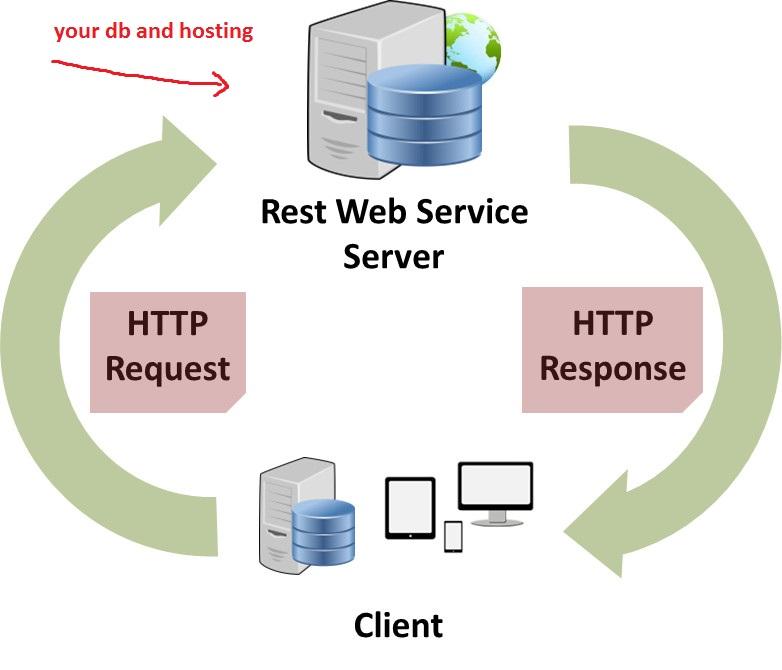
Веб-разработка – это огромная область с огромным набором концепций, терминов, инструментов и технологий. Для людей, только начинающих веб-разработку, этот ландшафт часто сбивает с толку – неясно, что представляет собой большинство из этих элементов, а тем более как они сочетаются друг с другом.
В этой серии представлен обзор основных концепций и технологий веб-разработки, что это за элементы, зачем они нужны и как они связаны друг с другом. Это не полностью исчерпывающий справочник по веб-разработке и не руководство “как создавать приложения”. Вместо этого это карта территории, предназначенная для того, чтобы дать вам представление о том, как выглядит ландшафт, и достаточно информации, чтобы вы могли изучить эти термины и темы более подробно, если это необходимо.
Некоторые описания будут в большей степени ориентированы на разработку современных клиентских приложений с использованием JavaScript, но большинство тем в серии достаточно фундаментальны, чтобы их можно было применить и к серверно-ориентированным приложениям.
Новые термины будут выделены курсивом. Я приведу ссылки на некоторые из них, но рекомендую вам самим искать определения. Кроме того, некоторые описания будут упрощены, чтобы не занимать слишком много места или иметь дело с крайними случаями. Этот пост, в частности, не пытается стать руководством “как программировать” или полной ссылкой на JS, но укажет на общие ошибки и отличия от других языков, таких как Java, C ++ и Python.
В MDN JavaScript docs есть полный набор ресурсов по всему, что связано с JavaScript, AJAX и функциональностью браузера
В современном руководстве по JavaScript содержится информация о встроенных API AJAX и хранилище браузера.
JSON
Обзор JSON
JSON – наиболее широко используемый формат передачи данных для веб-приложений. JSON – это сокращение от “JavaScript Object Notation” и является адаптацией синтаксиса JS object / array для использования в качестве формата данных. Все основные языки программирования имеют встроенную поддержку чтения и записи данных в формате JSON, но это, естественно, вписывается в JavaScript. JSON стал де-факто стандартным форматом передачи данных для API на основе HTTP, а некоторые базы данных даже поддерживают хранение и запрос содержимого документа JSON. (слайды: JSON)
Синтаксис JSON состоит из обычных объектов JS и определений массивов, включая примитивы, такие как числа, строки, логические значения и null. Однако в JSON есть некоторые дополнительные правила и ограничения по сравнению с обычным синтаксисом JS:
- Никаких переменных
- Комментариев нет
- Все ключи объекта должны быть заключены в двойные кавычки
- Конечный ключ в объектах и конечный элемент в массивах могут не иметь конечной запятой
Верхний уровень данных JSON может быть либо объектом, либо массивом (слайды: (слайды: Примеры синтаксиса JSON))
Типичный документ JSON для списка объектов todo может выглядеть следующим образом:
[
{ "id": 0, "text": "Buy milk", "completed": false, "colors": ["red"] },
{ "id": 1, "text": "Clean yard", "completed": true, "colors": [] },
{
"id": 2,
"text": "Read book",
"completed": false,
"colors": ["red", "blue"]
}
]
Поскольку JSON является подмножеством синтаксиса JS, ему не хватает нескольких вещей, которые есть в обычном JS. Невозможность писать комментарии – часто упоминаемая проблема. Он также не имеет встроенной поддержки значений даты, поэтому они должны быть сериализованы в виде строк. Вы можете записывать числа в формате JSON любого размера, но поскольку сам JavaScript ограничен 64-разрядными числами с плавающей запятой, на практике это также ограничивает размер чисел, которые вы можете передавать через JSON.
Работа с JSON
Содержимое JSON должно быть сериализовано путем преобразования его в единую строку для передачи, а затем десериализовано обратно в реальные объекты после его получения.
Язык JS поддерживает это с помощью пары встроенных функций: JSON.stringify(value) преобразует любое допустимое значение (объект, массив, примитив) в полную строку. JSON.parse(string) десериализует строку текста JSON обратно в соответствующие значения.
При отправке содержимого в формате JSON по HTTP в запросе или ответе должен использоваться заголовок content-type: application/json.
Большинство серверных фреймворков имеют встроенные ярлыки для возврата ответа в формате JSON. Эти методы часто позволяют возвращать объект или массив напрямую, а платформа заботится о сериализации данных в формате JSON и установке правильных заголовков HTTP. Например, платформа Express server для Node имеет res.json(obj).
AJAX
AJAX – это термин, используемый для описания выполнения HTTP-запросов через JavaScript в фоновом режиме страницы без ее перезагрузки. Это аббревиатура, которая первоначально расшифровывалась как “Асинхронный JavaScript и XML”. На момент создания фразы XML был стандартным форматом передачи данных, используемым для большинства запросов. С тех пор JSON полностью заменил XML в качестве стандартного формата передачи данных. Сегодня термин “AJAX-запрос” обычно относится к выборке данных в формате JSON с веб-сервера по протоколу HTTP.
Браузеры имеют пару встроенных API, которые используются для создания AJAX-запросов: XMLHttpRequest (XHR) и fetch. XHR обычно считается неуклюжим, низкоуровневым и сложным в использовании дизайном API. fetch задуман как более современная замена, но все еще имеет некоторые заметные недостатки в своем дизайне. Из-за этого большинство приложений используют стороннюю библиотеку, которая использует один из этих двух встроенных методов для предоставления альтернативного API, который проще в использовании.
Примечание: Термин “API” всегда означает “другой код, который вы вызываете, чтобы что-то сделать”, но в зависимости от контекста это может означать “фактическую функцию, которую вы вызываете в своем коде”, или “удаленный запрос к серверу для извлечения некоторых данных”. В разделе “AJAX” “API” относится к фактическим функциям, которые вы вызываете в своем JS-коде. В разделе “Протоколы передачи данных” ниже говорится об удаленных сетевых запросах на получение данных.
Браузеры могут кэшировать некоторое содержимое HTTP-ответа. Чаще всего это происходит со статическими файлами, такими как HTML, CSS и изображения, но другие ответы HTTP-данных также могут быть кэшированы. Это, скорее всего, произойдет, если HTTP-запрос использует метод HTTP GET. Несколько HTTP-заголовков также влияют на кэширование.
API и библиотеки AJAX
Использование AJAX API обычно подразделяется на три категории:
- Встроенные
XMLHttpRequestиfetchAPI - Сторонние библиотеки-оболочки, такие как
axiosиjQuery, которые обертывают основные API - Абстракции для извлечения данных более высокого уровня, которые используют другие API внутри
Существует множество сторонних библиотек-оболочек AJAX, поэтому мы кратко рассмотрим здесь пару наиболее популярных опций.
XMLHttpRequest
XMLHttpRequest обычно называемый “XHR”, является оригинальным браузером API для выполнения AJAX-запросов. Он был представлен Internet Explorer примерно в 1999 году и добавлен другими браузерами в течение следующих нескольких лет. Несмотря на свое название, его можно использовать для передачи любого контента по HTTP, а не только XML.
API XHR основан на создании экземпляра объекта XHR и назначении ему обратных вызовов для различных событий жизненного цикла запроса. Общеизвестно, что с таким подходом сложно работать. (слайды: примеры XHR)
XHR поддерживается во всех браузерах и в Node.js . Поскольку он доступен везде и существует дольше, он часто используется в качестве основной реализации других библиотек AJAX.
fetch
fetch API – это более новый встроенный в браузер API, предназначенный для замены XHR. Он имеет более приятный синтаксис и использует обещания для обработки ответов. (слайды: fetch примеры)
Типичный fetch запрос может выглядеть так:
fetch('http://example.com/api/users')
.then((response) => response.json())
.then((users) => {
// do something with users data
});
Однако у fetch есть некоторые особенности поведения, которые часто удивляют или раздражают разработчиков:
fetchотклоненное обещание возвращается только в том случае, если фактический сетевой запрос не удался полностью. Пока сервер возвращает ответ,fetchбудет возвращать успешно разрешенное обещание, даже если код состояния HTTP был ошибкой HTTP 4xx или 5xx.- Первоначальный
fetch('/some/url')вызов возвращает обещание, содержащееResponseобъект. Этот объект не является фактическими сериализованными данными с сервера. Вместо этого требуется второй вызов, чтобы запросить ответ на возврат содержимого тела запроса в определенном формате, таком как JSON. fetchпо умолчанию не отправляет файлы cookie на сервер – вы должны включитьcredentials: 'same-origin'опциюfetchпри отправке JSON не выполняется автоматическая привязка объектов или установка заголовков – вы должны выполнить эти шаги самостоятельно
Кроме того, fetch не поддерживается в Internet Explorer или Node.js .
Из-за этого очень часто используется библиотека, которая оборачивает XHR или fetch. Для случаев, когда вы хотите использовать, fetch но это недоступно в вашей целевой среде, есть полизаполнения для добавления переопределения fetch в средах, которые его не поддерживают, например isomorphic-fetch.
Axios
Axios – это широко популярная библиотека-оболочка AJAX. Его дизайн API основан на классах “Ресурсов”, которые были частью AngularJS 1.x, в частности, на структуре его объектов ответа.
Axios делает обычные задачи довольно простыми. axios Объект по умолчанию имеет методы .get() и .post(), которые возвращают обещания. .post() Метод принимает значение данных в качестве аргумента и, если оно указано, автоматически преобразует его в JSON и добавляет заголовки к запросу. Объекты ответа Axios автоматически десериализуют содержимое JSON, и основное содержимое всегда доступно в response.data. Типичный запрос может выглядеть следующим образом:
axios.get('http://www.example.com/api/users').then((response) => {
// do something with response.data
});
Поскольку он использует XHR внутри, он работает во всех браузерах, а также в Node.
Axios также предоставляет некоторые мощные возможности, такие как “перехватчики”, которые позволяют изменять запросы и ответы. Это часто используется для добавления заголовков аутентификации или преобразования данных.
jQuery
Исторически jQuery использовался для обеспечения мощных манипуляций с DOM, сглаживая различия DOM API между браузерами. jQuery также включает в себя оболочку AJAX $.ajax(). Учитывая трудности в работе с простым XHR API, AJAX-оболочка jQuery стала еще одной важной причиной его популярности. (слайды: jQuery AJAX)
С jQuery AJAX API удобнее работать, чем с XHR, но определенно все еще показывает, что он был разработан в более раннюю эпоху использования JS. В первую очередь требуются обратные вызовы success и error, а не работа с обещаниями. У него есть возможность обрабатывать ответы, возвращая предшественник обещаний, называемый “отложенным”, и может автоматически десериализовать данные JSON.
Если вы работаете над простым сайтом и уже используете jQuery для других целей, разумно использовать jQuery для выполнения вызовов AJAX. В противном случае предпочитайте использовать современные опции, такие как fetch или axios. Определенно не добавляйте jQuery на сайт только для выполнения вызовов AJAX.
Другие библиотеки запросов
Многие инструменты и фреймворки поставляются со своими собственными оболочками HTTP-запросов. Например, AngularJS 1.x имел $http общие запросы и $resource класс более высокого уровня для работы с REST API, в то время как современный Angular имеет HttpClient сервис.
Поскольку fetch API имеет несколько недостатков в своем дизайне, многие пользователи предпочитают писать свою собственную fetch оболочку для настройки поведения, обычно путем автоматического преобразования данных JSON и отклонения обещаний в ответах HTTP 4xx / 5xx.
С другой стороны, redaxios это повторная реализация большей части axios API в виде небольшой оболочки вокруг fetch.
Варианты HTTP-запросов
HTTP по своей сути является протоколом запроса / ответа. Это означает, что сервер никогда не сможет инициировать отправку сообщения клиенту самостоятельно. Однако во многих случаях серверу необходимо отправлять данные клиенту на основе события, произошедшего на сервере.
За прошедшие годы сообщество придумало несколько обходных путей. Современным решением этой проблемы является Websockets, но полезно знать и об этих других методах.
Polling
Polling – самый простой вариант для реализации. Клиент постоянно отправляет запросы на сервер каждые несколько секунд по таймеру. Однако обычно это неэффективно – большую часть времени сервер не будет сообщать ничего нового, поэтому новый запрос – пустая трата времени и пропускной способности.
Long Polling
Long Polling – это разновидность подхода к опросу. Вместо того, чтобы постоянно отправлять запросы, клиент открывает один запрос на сервер. Если у сервера нет сообщений для отчета, он переводит запрос в спящий режим. У клиента все еще открыто соединение, и он продолжает ждать ответа от сервера. В конце концов, у сервера либо появляется что-то новое для отчета, либо истекает таймер. В этот момент он запускает запрос и, наконец, отправляет ответ на исходное соединение с открытым запросом.
Затем клиент немедленно делает другой запрос, и серверу снова либо нужно что-то немедленно отправить обратно, либо он отключается от запроса.
Этот подход требует некоторой координации внутри сервера, но более эффективен с точки зрения пропускной способности.
Потоковая передача по HTTP
Как только клиент открывает HTTP-соединение, сервер может продолжать отправлять данные по открытому соединению, не закрывая ответ, оставляя его открытым на неопределенный срок.
События, отправленные сервером
События, отправляемые сервером, представляют собой особую форму потоковой передачи HTTP, которая фактически является частью спецификации HTTP. Клиент создает EventSource объект и добавляет обратный вызов прослушивателя событий, а сервер со временем записывает специально отформатированный контент в ответ.
Websockets
Все эти основанные на HTTP подходы к двусторонней передаче сообщений и данных имеют определенные ограничения. Websockets были созданы для устранения этих ограничений. Websockets позволяют открывать постоянное соединение между клиентом и сервером, где любая сторона может отправлять сообщения по соединению в любое время. (слайды: websockets)
Websocket начинается как стандартный HTTP-запрос, но клиент добавляет заголовок, сообщающий серверу, что он хочет “обновить” соединение с websocket. Веб-сокет концептуально похож на реальный сетевой сокет уровня операционной системы, и, как и все HTTP-запросы, данные отправляются через реальный сокет. Но это абстракция более высокого уровня, и с точки зрения API она гораздо более ограничена по сравнению с низкоуровневым сокетом ОС.
После создания любая сторона может добавлять прослушиватели событий для обработки полученных сообщений и отправки сообщений по соединению. Сообщения могут содержать текстовое или двоичное содержимое.
Сегодня websockets – это стандартный подход, используемый для предоставления текущих обновлений страницы после ее обновления, например, обновлений спортивных результатов.
CORS
HTTP-запросы часто связаны с проблемами безопасности и авторизации. В рамках этого браузеры специально внедряют ограничения, такие как политика того же источника, чтобы скрипты могли взаимодействовать только с ресурсами, загруженными с того же URL-адреса сервера. Кроме того, сервер может захотеть разрешить взаимодействие только со своими собственными сценариями и клиентским кодом, который он обслуживал, вместо запросов от любого произвольного сайта или клиента.
Браузеры обеспечивают это с помощью совместного использования ресурсов разных источников (CORS). По умолчанию запрос AJAX на любой URL, отличный от исходного URL для главной страницы, заставит браузер сделать предварительный запрос, чтобы спросить сервер: “Вы согласны с тем, что другие сайты запрашивают у вас данные?”. Затем сервер может ответить набором шаблонов URL, которые разрешены для успешной отправки запросов, или значением, указывающим “все запросы в порядке”. Если текущий клиент соответствует этому шаблону, браузер действительно отправит реальный запрос.
CORS – частый источник путаницы для разработчиков, которые просто пытаются сделать запрос и удивляются, когда браузер блокирует его.
Обратите внимание, что только браузеры реализуют CORS – HTTP-запросы, выполняемые вне браузера, например, с другого сервера или в других средах, отличных от браузера, не применяют CORS. Это также может сбивать с толку – “это сработало в моем тестовом клиенте CLI tool / API, почему это не работает в браузере?”.
Протоколы передачи данных
HTTP предоставляет стандартный механизм для отправки некоторого вида запроса и ответа на сервер. Однако существует множество способов, которыми сервер может структурировать свои URL-адреса и ожидаемый формат запросов и ответов. Чтобы написать код, который отправляет запросы на сервер, вы должны знать, какую структуру и форматы запросов сервер ожидает от вашего клиента использовать.
Существует множество вариантов того, как структурированы API серверных данных, но есть несколько общих категорий структур API, которые вы будете часто видеть. (слайды: Подходы к разработке AJAX API)
При всех этих подходах сервер определяет конкретные конечные точки – комбинации URL-адресов, методов HTTP и ожидаемых форматов запроса / ответа.
REST
REST означает “Передача репрезентативного состояния”. REST API – это API на основе HTTP, который использует URL-адреса и методы HTTP в качестве основного подхода для определения того, какой запрос делает клиент, и как сервер должен обрабатывать этот запрос.
REST API часто используются для CRUD (создание / извлечение / обновление / удаление) приложений, где приложение концептуально выполняет операции по обновлению данных в базе данных на сервере (“создайте эту вещь”, “дайте мне список этих вещей”, “обновите эту вещь”, “удалите эту вещь”).
Часто возникают споры о том, что именно представляет собой настоящий REST API, но в целом REST API:
- Предлагает разные URL-адреса для каждого вида “ресурса”, который он поддерживает
- Expects different HTTP methods to be used for different kinds of operations on the same resource URL. Typically, HTTP
POST/GET/PUT/DELETEmap to relevant CRUD operations. - Returns different HTTP status codes to indicate success or failure of the request
- Expects key pieces of data like item IDs to be included as part of the actual URL
Example REST API usage might look like:
- Получить список пользователей:
GET /users - Получите одного пользователя:
GET /users/42 - Создайте одного пользователя:
POST /users/42(тело:{name : "Mark"}) - Обновить пользователя:
PUT /users/42(тело:{name : "Mark"})
Многие серверные веб-фреймворки имеют встроенную поддержку для определения набора конечных точек REST API на основе метаданных.
RPC
RPC означает “удаленный вызов процедуры”. Это общий стиль сетевого запроса, который предназначен для имитации обычного вызова функции в вашем коде, но с фактической логикой, выполняемой на каком-либо другом сервере. За эти годы было создано множество инструментов RPC для многих языков. Здесь основное внимание уделяется HTTP-запросам в стиле RPC.
Подход в стиле RPC описывает “методы”, которые нужно “вызывать”, вместо “ресурсов”, с которыми нужно “работать”. В отличие от REST API, API в стиле RPC, скорее всего, определяет URL-адреса, пути к которым выглядят как глаголы или имена функций вместо существительных.
Например, подход к RPC-серверу на основе HTTP может выглядеть следующим образом:
- Получите список пользователей:
GET /getUsers - Получить одного пользователя:
POST /getUser(тело:{userId : 42}) - Создайте одного пользователя:
POST /createUser(тело:{userId : 42, name : "Mark"}) - Обновите одного пользователя:
POST /updateUser(тело:{userId : 42, name : "Mark"})
С другой стороны, может существовать единственная конечная точка URL, и запрос может содержать имя “метода для вызова” в теле. Спецификация JSON-RPC использует этот подход:
POST /jsonrpc(основная часть:{"method": "createUser", userId : 42, name : "Mark"})
В любом случае, в ответе, скорее всего, будет код состояния HTTP 200, указывающий, что сервер успешно вернул ответ, но в содержимом ответа может быть какое-то поле, указывающее, удалась ли фактическая операция, например {status: 'failed'}.
GraphQL
GraphQL – это относительно недавний протокол передачи данных, созданный Facebook. Концептуально GraphQL – это определенный формат для содержимого запросов API и ответов. Кроме того, существует экосистема клиентских и серверных инструментов, которые обычно используются, чтобы абстрагировать детали создания запроса в формате GraphQL, обработки запроса на сервере и извлечения запрошенных данных, правильного форматирования ответа и кэширования данных на клиенте. Большинство обсуждений “использования GraphQL” предполагают использование наиболее популярных библиотек и инструментов для работы с GraphQL.
С GraphQL сервер предлагает единую конечную точку URL и определяет схемы, которые описывают, какие типы данных он поддерживает и как они связаны друг с другом. Клиент отправляет запрос GraphQL query, который запрашивает некоторое подмножество этих типов данных и определяет ожидаемую структуру формата ответа. Затем сервер разрешает запрошенные типы данных, извлекает запрошенные поля для каждого типа, форматирует ответ в соответствии с запросом клиента и отправляет данные обратно. Сервер также может поддерживать мутации, которые позволяют клиенту создавать / обновлять / удалять данные и подписки на изменения результатов запроса с течением времени.
Запросы GraphQL почти всегда представляют собой HTTP-сообщения, а подписки обычно создаются поверх websockets.
Синтаксис запроса GraphQL чем-то напоминает JSON, но без запятых или значений:
{
hero {
name
friends {
name
}
}
}
что может привести к такому JSON-ответу от сервера:
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{"name": "Luke Skywalker"},
{"name": "Han Solo"},
{"name": "Leia Organa"}
]
}
}
}
GraphQL переносит большую часть сложности запросов на сервер и предоставляет клиентам большую гибкость в том, какие данные они хотят запросить. Это может упростить случаи, когда разные части приложения должны извлекать разные подмножества одних и тех же данных, и уменьшить необходимость совершать многочисленные вызовы для извлечения связанных значений. С другой стороны, может быть сложнее иметь дело с такими вещами, как аутентификация и бизнес-логика, как часть разрешения данных на сервере, а самые популярные клиенты GraphQL очень тяжелые.
Хранилище в браузере
В дополнение ко всем этим сетевым запросам на выборку данных браузеры также предлагают несколько инструментов для хранения данных в самом браузере. Обычно они используются для управления данными, относящимися к сеансам пользователя и настройкам, но могут использоваться и для других сценариев.
Файлы cookie
Браузеры позволяют серверам устанавливать cookies – небольшие фрагменты текста, связанные с заданным URL. Любые файлы cookie, установленные сайтом, будут включены в будущие запросы к этому сайту. Файлы cookie обычно ограничены парой КБ в длину и чаще всего используются для хранения уникального идентификатора сеанса, который может быть прочитан сервером для извлечения дополнительных данных сеанса из базы данных или памяти. У файлов cookie могут быть временные метки истечения срока действия, установленные сервером.
Файлы cookie могут быть источником проблем с безопасностью. Сервер может добавить HttpOnly атрибут при настройке файла cookie, чтобы гарантировать, что JS-код не сможет прочитать или изменить этот файл cookie.
localStorage
localStorage это API браузера, который позволяет клиентскому коду сохранять данные строки ключа / значения, а затем извлекать их позже. localStorage сохраняется неопределенно долго, поэтому часто используется для сохранения пользовательских настроек, чтобы их можно было перезагрузить при следующем посещении страницы пользователем. Примером этого может бытьlocalStorage.setItem('userPrefs', JSON.stringify(userData)), а затем обратный процесс при загрузке страницы. Данные в localStorage могут быть прочитаны только кодом из того же источника и ограничены размером около 2 МБ.
sessionStorage
sessionStorage использует те же базовые методы API, что и localStorage, но изолированно для каждой вкладки. Он будет сохраняться между перезагрузками вкладки, но будет удален, когда пользователь закроет вкладку.
indexedDB
Более мощная система хранения данных в стиле базы данных, которая может хранить большие объемы данных.
Маршрутизация URL-адресов клиентов
В HTTP и Servers мы говорили об идее маршрутизации: определение поведения приложения на основе URL. Для серверов приложений маршрутизация означает просмотр URL и метода HTTP и выбор правильной логики обработчика приложений для обработки этого запроса.
Клиентские приложения могут выполнять свою собственную форму маршрутизации. Браузеры предлагают доступ к текущему URL-адресу через window.location и к истории URL-адресов браузера через history объект.
Клиентские приложения могут анализировать URL-адрес и использовать его в качестве основы для динамического отображения и скрытия частей пользовательского интерфейса без необходимости отправлять дополнительный запрос на сервер. Маршрутизаторы на стороне клиента обычно предлагают специальные формы тега ссылки, которые обрабатывают клики, вызывая history.push('/new-route') для изменения URL, а затем считывают обновленный маршрут, чтобы переключиться на отображение другой части пользовательского интерфейса.
Однако маршрутизация клиентов добавляет дополнительные сложности. Если браузер пытается перезагрузить перенаправленный клиентом URL-адрес самостоятельно, сервер теперь должен каким-то образом обработать этот URL-адрес с допустимым ответом. Как правило, сервер настроен таким образом, что если подобный URL-адрес /some-route не распознается, он возвращает всю индексную страницу с полным пакетом JS в качестве ответа, точно так же, как если бы браузер запрашивал / URL. Как только контент загружен, клиентский маршрутизатор включается, видит, что /some-route это активный URL-адрес, и немедленно отображает соответствующий контент на стороне клиента.
Полезные ресурсы:
- JSON
- AJAX
- HTTP Request Variations
- Websockets
- CORS
- Data Transfer Protocols
- Browser Storage
- Client Routing
Оригинал: https://blog.isquaredsoftware.com/2020/11/how-web-apps-work-ajax-apis-data/
