
Цель этой статьи – предоставить некоторые инструкции о том, как проводить анализ результатов A / B-теста для примера сценария с использованием R, оценивать результаты и делать выводы на основе анализа.
Прежде чем мы начнем, давайте рассмотрим, что означает A / B-тест, для чего он обычно используется и каковы некоторые из его ограничений.
Определение
A / B-тестирование, также известное как сплит-тестирование, – это общая методология, используемая в Интернете, когда вы хотите протестировать новый продукт или функцию. Цель состоит в том, чтобы разработать эксперимент, который будет надежным и даст воспроизводимые результаты, чтобы принять обоснованное решение запускать или нет.
Как правило, этот тест включает сравнение двух веб-страниц, показывающих два варианта A и B, с аналогичным количеством посетителей и вариант, который дает лучший коэффициент конверсии.
В основном это эксперимент, в ходе которого два или более вариантов одной и той же веб-страницы сравниваются друг с другом, отображая их для посетителей в реальном времени, чтобы определить, какой из них лучше подходит для данной цели. A / B-тестирование не ограничивается только веб-страницами, вы можете A / B-тестировать свои электронные письма, всплывающие окна, формы регистрации, приложения и многое другое.
Обычно одна из многих причин, по которым проводится A / B-тест, заключается в том, чтобы убедиться, что новые функции, которые планируется внедрить, действительно оказывают измеримое (положительное) влияние на намеченную цель, связанную с желанием ввести такие функции.
Ограничения
A / B-тестирование – один из многих инструментов для оптимизации конверсии. Это не самостоятельное решение. Это не решит всех ваших проблем с конверсией. Он не может исправить типичные проблемы, возникающие с беспорядочными данными. Вам нужно сделать больше, чем просто A / B-тест, чтобы действительно улучшить конверсию.
Теперь давайте погрузимся в практический пример тематического исследования. Наборы данных и полную информацию анализа можно найти на GitHub Если вам нужна какая – то помощь понимание и использование Github, есть полезная ссылка для начинающих здесь.
Пример использования
Представьте, что у нас есть результаты A / B-тестов с двух сайтов бронирования отелей. (Примечание: данные созданы так, чтобы они выглядели как настоящие.) Нам необходимо провести A / B-тестовый анализ данных, сделать выводы на основе данных и дать рекомендации руководству или продуктовым командам.
Примечание. Приведенный ниже анализ предполагает небольшое знание статистических концепций, чтобы сделать его кратким и точным.
Сводка набора данных
- Вариант A – это контрольная группа, которая отображает существующие продукты или функции на веб-сайте.
- Вариант B – это экспериментальная группа, которая экспериментирует с новой версией продукта или функции, чтобы узнать, нравится ли она пользователям или увеличивает ли это количество бронирований (конверсий).
- Преобразовано – на основе данного набора данных есть две категории, определяемые логическими значениями (Истина или ложь):
- Конвертировано = Истина, когда клиент успешно совершает бронирование
- Converted = False, когда клиент посещает сайты, но не бронирует
Как проверить гипотезу
Нулевая гипотеза
Обе версии A и B имеют одинаковую вероятность привлечения клиентов к бронированию или конверсии. Другими словами, нет никакого эффекта или разницы между версией A и B.
Альтернативная гипотеза
Обе версии A и B имеют разную вероятность привлечения клиентов к бронированию или конверсии. Существует разница между версией A и B. Версия B лучше, чем A, с точки зрения увеличения числа заказов клиентов. PExp_B! = Pcont_A
Анализ
Давайте вместе проведем анализ. Загрузите набор данных здесь . Обратите внимание, что для этого у вас должен быть установлен RStudio.
1.Подготовьте набор данных и загрузите библиотеку tidyverse, которая содержит соответствующие пакеты, используемые для анализа.
library (tidyverse)
setwd («~ egot _ \\ Projects \\ ABTest») # создайте свой собственный каталог
ABTest <- read.csv («Website Results.csv», header = TRUE) # Использование read.csv base R file import функция, чтобы данные можно было импортировать в фрейм данных в RStudio.
save (ABTest, file = "~ rda \\ ABTest.rda") # сохранить в своем собственном каталоге2. Отфильтруем конверсии для вариантов A и B и вычислим соответствующие коэффициенты конверсии.
#2a. let's filter out conversions for variant_A
conversion_subset_A <- ABTest %>% filter(variant == "A" & converted == "TRUE")
#2b.Total Number of Conversions for variant_A
conversions_A <- nrow(conversion_subset_A)
#2c. Number of Visitors for variant_A
visitors_A <- nrow(ABTest %>% filter(variant == "A"))
#2d. Conversion_rate_A
conv_rate_A <- (conversions_A/visitors_A)
print(conv_rate_A) #0.02773925
#2e. let's take a subset of conversions for variant_B
conversion_subset_B <- ABTest %>% filter(variant == "B" & converted == "TRUE")
#2f. Number of Conversions for variant_B
conversions_B <- nrow(conversion_subset_B)
#2g. Number of Visitors for variant_B
visitors_B <- nrow(ABTest %>% filter(variant == "B"))
#2h. Conversion_rate_B
conv_rate_B <- (conversions_B/visitors_B)
print(conv_rate_B) #0.050684933. Давайте вычислим относительный рост, используя коэффициенты конверсии A и B. Повышение – это процент от увеличения.
uplift <- (conv_rate_B - conv_rate_A) / conv_rate_A * 100
uplift # 82,72%
#B лучше, чем A на 83%. Этого достаточно, чтобы определить победителя.5. Рассчитаем z-оценку.
№5а. Вычислите Z-оценку, чтобы мы могли определить значение p
z_score <- d_hat / SE_pool
print (z_score) # 2.2495466. Используя этот z-показатель, мы можем быстро определить p-значение через справочную таблицу или с помощью приведенного ниже кода:
# 5b. Вычислим p_value, используя значение z_score p_value <- pnorm (q = -z_score, mean = 0, sd = 1) * 2 print (p_value) # 0,02447777
7. Рассчитаем доверительный интервал для пула.
#7a. Let's compute Confidence interval for the pool using pre-calculated results
ci <- c(d_hat - MOE, d_hat + MOE)
ci #0.002953777 0.042937584
#7b. Using same steps as already shown, let's compute the confidence
#interval for variants A separately
X_hat_A <- conversions_A/visitors_A
se_hat_A <- sqrt(X_hat_A*(1-X_hat_A)/visitors_A)
ci_A <- c(X_hat_A - qnorm(0.975)*se_hat_A, X_hat_A + qnorm(0.975)*se_hat_A)
print(ci_A) #0.01575201 0.03972649
# Using same steps as already shown, let's compute the confidence
#interval for variants B separately
X_hat_B <- conversions_B/visitors_B
se_hat_B <- sqrt(X_hat_B*(1-X_hat_B)/visitors_B)
ci_B <- c(X_hat_B - qnorm(0.975)*se_hat_B, X_hat_B + qnorm(0.975)*se_hat_B)
print(ci_B) #0.03477269 0.066597178. Давайте визуализируем полученные результаты во фрейме данных (таблица):
vis_result_pool <- data.frame(
metric=c(
'Estimated Difference',
'Relative Uplift(%)',
'pooled sample proportion',
'Standard Error of Difference',
'z_score',
'p-value',
'Margin of Error',
'CI-lower',
'CI-upper'),
value=c(
conv_rate_B - conv_rate_A,
uplift,
p_pool,
SE_pool,
z_score,
p_value,
MOE,
ci_lower,
ci_upper
))
vis_result_poolМодель
На основе проведенных до сих пор вычислений я создал модель для вычисления ABTests. Вы можете просто добавить свой файл с соответствующими результатами ABTest в том же формате, что и файл, который я использовал, и как только вы запустите эту модель, ваш результат ABTest будет вычислен и возвращен вам в течение нескольких секунд.
Compute_ABTest_Results <- function(loadfile) {
ABTest <- read.csv(loadfile, header = TRUE)
conversion_subset_A <-
ABTest %>% filter(variant == "A" & converted == "TRUE")
conversions_A <- nrow(conversion_subset_A)
visitors_A <- nrow(ABTest %>% filter(variant == "A"))
conv_rate_A <- (conversions_A / visitors_A)
conversion_subset_B <-
ABTest %>% filter(variant == "B" & converted == "TRUE")
conversions_B <- nrow(conversion_subset_B)
visitors_B <- nrow(ABTest %>% filter(variant == "B"))
conv_rate_B <- (conversions_B / visitors_B)
uplift <-
(conv_rate_B - conv_rate_A) / conv_rate_A * 100
p_pool <-
(conversions_A + conversions_B) / (visitors_A + visitors_B)
SE_pool <-
sqrt(p_pool * (1 - p_pool) * ((1 / visitors_A) + (1 / visitors_B)))
MOE <- SE_pool * qnorm(0.975)
d_hat <- conv_rate_B - conv_rate_A
z_score <- d_hat / SE_pool
p_value <- pnorm(q = -z_score,
mean = 0,
sd = 1) * 2
lower = d_hat - qnorm(0.975) * SE_pool
upper = d_hat + qnorm(0.975) * SE_pool
vis_result_pool <- data.frame(
metric = c(
'Estimated Difference',
'Relative Uplift(%)',
'pooled sample proportion',
'Standard Error of Difference',
'z_score',
'p-value',
'Margin of Error',
'CI-lower',
'CI-upper'
),
value = c(
conv_rate_B - conv_rate_A,
uplift,
p_pool,
SE_pool,
z_score,
p_value,
MOE,
ci_lower,
ci_upper
)
)
return(vis_result_pool)
}
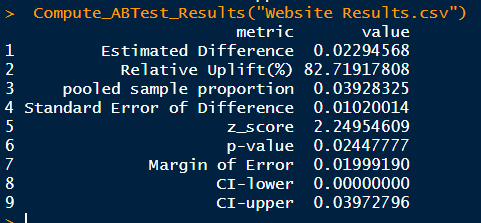
10. Наконец, давайте визуализируем результаты A и B, используя нормальное распределение.
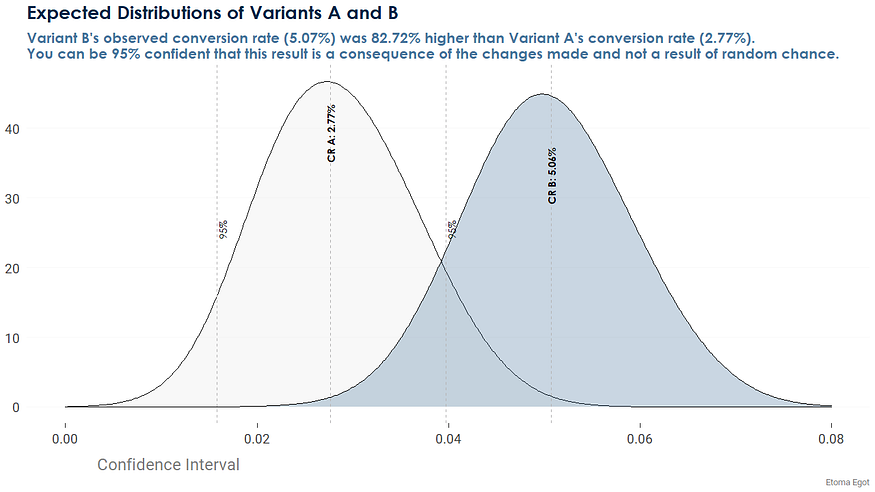
Выводы и рекомендации
1. Имеется 721 обращение и 20 переходов для варианта A и 730 обращений и 37 переходов для варианта B.
2. Относительный рост на 82,72% на основе коэффициента конверсии для A = 2,77%, коэффициента конверсии для B = 5,07%. Следовательно, вариант Б лучше А на 82,72%.
3. P-значение, вычисленное для этого анализа, составило 0,02448 (p <0,05 или p ниже 5% уровня значимости). Следовательно, результаты тестов демонстрируют сильную статистическую значимость. Вы можете быть уверены на 95%, что этот результат – следствие внесенных изменений, а не случайный результат.
4. На основании вышеупомянутых результатов, которые показывают сильную статистическую значимость. вам следует отклонить нулевую гипотезу и приступить к запуску.
5. Следовательно, принять вариант «Б» и развернуть его для 100% пользователей.
