
При типичной реализации DWBI мы уже знаем некоторые основные шаблоны проектирования или советы, которые следует запомнить, например –
1. OLTP против OLAP — Какие существуют транзакции ?
2. Обработка в реальном времени против пакетной обработки — Какая там обработка?
3. Структурированные и полуструктурированные данные — Какие данные хранятся, обрабатываются в DW?
4. ETL против ELT — Какие операции , преобразования поверх исходных данных в DW?
5. Объем vs Скорость vs Достоверность — Какой объем, частота и разнообразие данных в DW? Каков ежедневный/ежемесячный/квартальный/годовой рост данных?
6. Предписывающая и прогнозирующая аналитика — Какая аналитика поверх данных, представленных в DW?
7. Конечные пользователи/ Бизнес — пользователи-Каковы различные типы пользователей, получающих доступ к данным из DW?
8. Параллелизм — Какие параллельные процессы выполняются в DW?
9. SLO против SLA — Каковы SLA, SLO приложений, запущенных поверх DW?
10. Производительность — Какова текущая производительность системы по сравнению с обновлением/доступностью системы ?
С помощью приведенных выше вопросов и ответов на них помогите нам спроектировать Хранилище данных. Мы можем легко рассчитать необходимые ресурсы, такие как вычислительные ресурсы и хранилище , требуемые пользователи — пользователи приложений и конечные пользователи, запущенные параллельные процессы и требуемое соглашение об уровне обслуживания. С помощью преобразований типа мы можем легко оценить доступные инструменты ETL, а также оценить собственные утилиты DW для реализации механизма push down для использования мощности DW для повышения производительности — это обычно используется в реализации типа ELT.
Теперь рассмотрим тот же набор вопросов и то, как они могут помочь нам получить шаблоны проектирования в реализациях GCP DW с помощью GCP BigQuery. Давайте проверим, как мы можем использовать эти вопросы:
1. OLTP против OLAP — Как мы уже знаем, BQ поддерживает реализацию типа OLAP
2. В режиме реального времени против пакетной обработки — BQ поддерживает как пакетную обработку, так и обработку в режиме реального времени. Существуют различия с точки зрения их реализации и доступности данных.
3. Структурированные и полуструктурированные данные — BQ поддерживает структурированные, полуструктурированные, а также форматы файлов экосистемы Bigdata, такие как Parquet, Avro и т. Д.
4. Разъемы и расширения ETL vs ELT — BQ интегрированы с большинством инструментов ETL. Мы можем использовать инструменты ETL, а также сервис GCP ETL — объединение данных для загрузки данных в DW.
5. Объем vs Скорость vs Достоверность — BQ является одним из управляемых сервисов GCP, который поддерживает растущие потребности в объеме данных, поддерживает разнообразие данных и их обработку.
6. Предписывающая и прогнозирующая аналитика — разъемы BQ доступны и интегрированы с большинством инструментов BI. Мы можем использовать инструменты BI, такие как Tableau, PowerBI , Looker или GCP native Data Studio, для отчетности и предписывающей аналитики. У BQ также есть BQ ML, который является расширением BQ для поддержки специалистов по обработке данных, которые лучше разбираются в SQL, чем в программировании. Мы можем запускать прогностические модели с помощью BQ ML и планировать их , использовать их для получения прогнозов.
7. Конечные пользователи/ Бизнес — пользователи-BQ позволяет нам создавать Федеративные представления или Авторизованные представления для настройки доступа конечных пользователей к DW/данным.
8. Параллелизм — В устаревших реализациях и даже в некоторых облачных сервисах существуют ограничения на одновременный доступ пользователей к данным, но в BQ у нас есть более широкие ограничения, где мы можем настраивать одновременный доступ через процессы или пользователей с помощью проекта BQ. Вы можете обратиться к моему следующему блогу о безопасности данных с помощью BQ, чтобы подробно разобраться в настройке доступа.
9. SLOs vs SLAs — BQ хорошо известен своей производительностью и временем выполнения запросов. Благодаря архитектуре BQ и пути доступа к данным мы можем сканировать огромные данные за несколько секунд. Конечные пользователи, а также соглашения об уровне обслуживания приложений зависят от того, как процессы и приложения, преобразования выполняются в BQ . Вы можете обратиться к моему следующему блогу для оптимизации производительности с помощью BQ для проектирования и разработки рабочих нагрузок на BQ
10. Производительность — Это важный фактор любой реализации DW, где проектирование процессов/рабочих нагрузок влияет на производительность DW. Хотя BQ хорошо известен своей производительностью , на это может повлиять неправильный SQLS, кодирование, разработка или миграция устаревшего кода, как и в BQ.
Хотя BQ является эффективным с точки зрения производительности , управляемым сервисом или бессерверным сервисом GCP, мы должны быть осторожны при реализации ETL или ELT, процессов, рабочих нагрузок или преобразований с помощью BQ. Производительность BQ зависит от способа разработки запросов , сканирования данных и т.д. Я хотел бы поделиться несколькими советами или шаблонами, полезными для дизайна BQ DW
- Разделите ваши данные — Определите горячие , теплые и холодные данные, присутствующие в вашей текущей системе, и распределите их по разным хранилищам.
2. Горячие данные— Данные, к которым часто обращаются, обрабатываются в DW. Храните эти данные как часть таблиц BQ, используя хранилище BQ
3. Теплые данные — Данные, к которым реже обращаются, на которые ссылаются или которые изменяются. Основываясь на отсутствии считывания или ссылки на эти данные, либо сохраните их как таблицу BQ, либо сохраните в корзине GCS и определите внешнюю таблицу поверх нее ( это зависит исключительно от доступности и использования данных).
4. Холодные данные — Данные, которые редко используются, или архивные данные, или исторические данные, на которые вряд ли будут ссылаться какие-либо отчеты или процессы. Я рекомендую хранить их в корзинах GCS вместо того, чтобы перемещать их в BQ. Это позволит сэкономить затраты на хранение BQ, так как стоимость хранения GCS на холодной линии или на ближней линии дешевле, чем стоимость хранения BQ. Поверх нее можно создать внешнюю таблицу, если вообще требуется доступ к ней.
5. Определите слои вашего DW — Определите различные уровни преобразования / обработки данных и создайте многоуровневый DW.
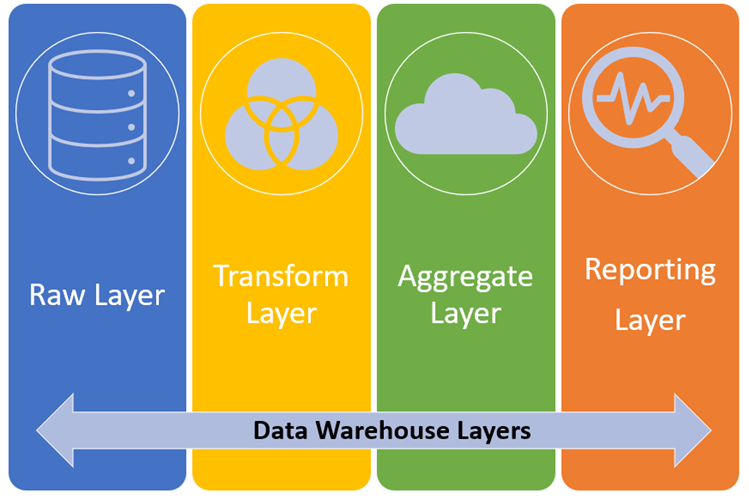
1. Необработанный слой/Этапный слой — Этот слой используется для хранения необработанных данных или исходных данных в исходном формате/форме . Храните исходные данные как есть. Таблицы в этом слое усекаются и загружаются. Обновите данные по мере их повторяемости.
2. Слой преобразования / Промежуточный слой — Этот слой используется для хранения преобразованных данных. Записывайте процессы/задания/конвейеры для чтения данных с необработанного слоя, применяйте преобразования и загружайте таблицы слоев для преобразования. Таблицы на этом уровне в основном содержат логику обновления и хранят пакетные данные в течение нескольких дней.
3. Совокупный слой / Целевой слой — Этот слой является конечным слоем, на котором данные, преобразованные из слоя преобразования, перемещаются в целевые таблицы. Таблицы на этом уровне в основном выполняют операции APPEND или UPSERT для объединения ежедневных изменений данных.
4. Уровень отчетности / BI — уровень / Аналитический уровень-Этот уровень предназначен для конечных пользователей, бизнес-пользователей, специалистов по обработке данных , аналитиков, работающих над примерами использования AI/ML. Этот уровень состоит из объединенных представлений или авторизованных представлений или ограниченного доступа к данным в соответствии с бизнес-требованиями.
5. Определите роли и пользователей DW — Мы знаем, что DW-это платформа данных, используемая различными пользователями в Организации, а также бизнесом/конечными пользователями. Определение ролей этих пользователей так же важно, как и определение уровней. Определите учетные записи служб (пользователей приложений) , пользователей разработчиков , бизнес-пользователей/конечных пользователей , команды BA , QA, DA и т.д.
6. Определите политики контроля доступа — Мы видели различные уровни обработки данных, использования и пользователей этих уровней. Контроль доступа является одним из наиболее важных аспектов проектирования для обеспечения безопасности данных. Существуют различные способы обеспечения безопасности данных, вы можете обратиться за тем же в мой следующий блог. Определение пользователей и ограничений доступа, политики для каждого уровня должны быть выполнены с помощью проектирования DW. RBAC является одним из методов реализации контроля доступа.
7. Определение процессов/рабочих нагрузок — На основе интеграции источников DW определите и определите различные типы трубопроводов, которые будут разработаны. Это важный этап, поскольку он требует затрат на техническое обслуживание, если он не разработан с применением некоторых общих правил или автоматизированных процессов. Вы можете обратиться к моему блогу для интеграции процессов с BQ.
8. Определите мониторинг, операции и техническое обслуживание — На основе разработанных трубопроводов и реализованной оркестровки, настройте процесс мониторинга или автоматизируйте его.
9. Определите сравнительный анализ расходов BQ — Как вы знаете , BQ-это управляемая служба GCP, которая занимается автоматическим масштабированием и управлением ресурсами. Если у вашего DW большой объем данных и их обработка, вам нужно быть осторожным при проектировании трубопроводов, чтобы избежать ненужных сканирований и выставления счета за то же самое. Вам необходимо ограничить ненужные проверки командами приложений. Для получения более подробной информации обратитесь к моему блогу о стоимости и оптимизации BQ. Настройка оповещений о выставлении счетов для использования BQ.
