
В этом руководстве мы узнаем, как извлечь данные с YouTube в четыре этапа. Используя R и API данных YouTube, мы можем получать информацию с канала или видео, такую как количество подписчиков, просматривать статистику и видеоинформацию.
В этом руководстве мы узнаем, как извлечь данные с YouTube в четыре этапа:
- Шаг 1: Получите свой API-ключ YouTube бесплатно
- Шаг 2: Установите R
- Шаг 3: Примеры вызовов API данных YouTube
- Шаг 4: Пример кода в R
Пример на шаге 4 представляет собой полный код. Просто отредактируйте ключи, каналы и вы готовы к работе.
Шаг 1: Получите API-ключ YouTube (бесплатно)
YouTube делится информацией через свой API, API данных YouTube.
Этот API является частью облачной платформы Google (GCP). Чтобы легально извлечь данные с YouTube, вам необходимо зарегистрироваться в облачном аккаунте Google, используя свой аккаунт Google.
Перейдя по следующей ссылке, вы попадете на страницу YouTube Data API v3. Это также будет включать параметры регистрации, если вы еще не являетесь участником Google Cloud.
Ссылка для подключения к API – https://console.cloud.google.com/apis/api/youtube.googleapis.com
Если вы впервые обращаетесь к этому API, вы увидите это на своем экране.
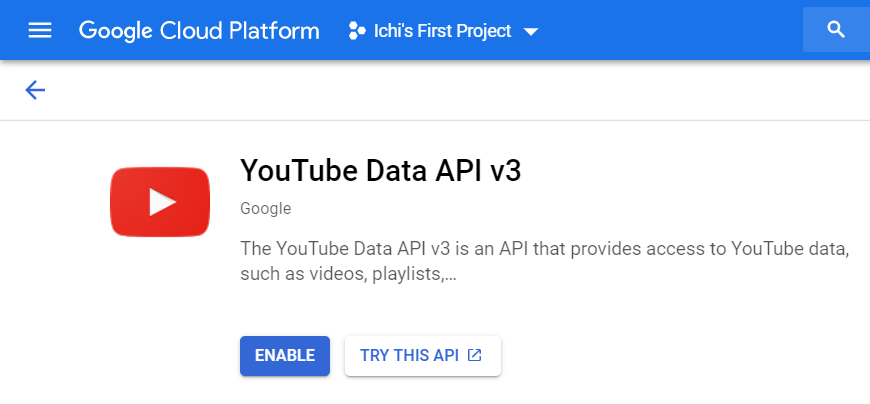
Нажмите Включить, и при следующем посещении вы увидите обзорную страницу.
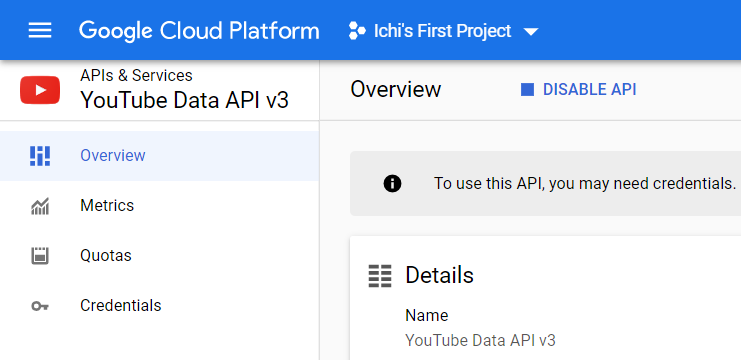
Давайте начнем создавать ваш API-ключ YouTube.
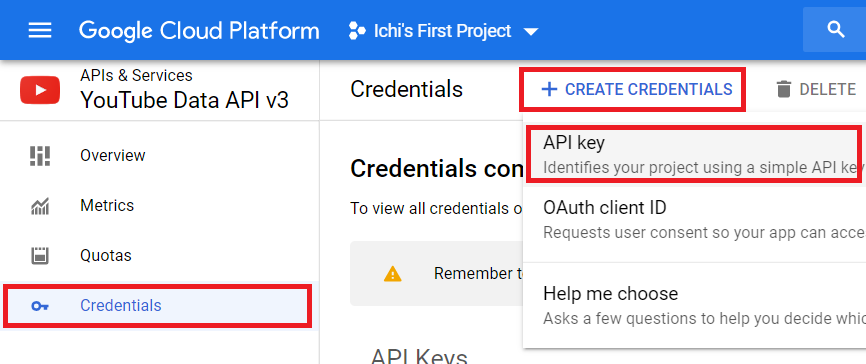
Нажмите на Учетные данные на левой боковой панели. Это приведет вас в раздел учетных данных. Нажмите Создать учетные данные и выберите ключ API.
Вы получите подтверждающее сообщение о том, что ваш API-ключ создан. Нажмите на ключ ограничения, чтобы убедиться, что ваш ключ будет использоваться только для извлечения данных YouTube.
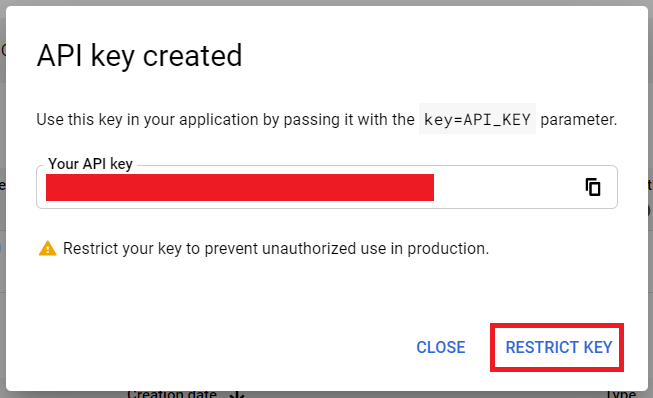
Важно: Не делитесь этим ключом API с другими людьми. Это предотвращает несанкционированное использование и потенциальное злоупотребление вашим ключом API.
Вы также заметите, что я не делюсь своим собственным ключом API на протяжении всего этого руководства.
Вы перейдете на страницу Ограничить и переименовать ключ API.
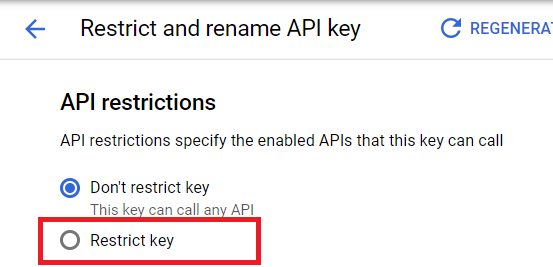
Найдите раздел с именем Ограничения API и выберите опцию Ограничить ключ. Здесь мы можем выбрать конкретные продукты, связанные с этим ключом.
Выберите YouTube Data API v3. Нажмите кнопку Сохранить.
Теперь у вас есть свой API-ключ!
Обратите внимание на значение этого ключа API. Когда мы начнем создавать наши примеры кодов ниже, вы сможете добавить свой ключ и начать извлечение данных YouTube.
Шаг 2: Установите R
Если вы уже установили R, вы можете пропустить этот раздел.
R – это инструмент для анализа данных. Здесь мы можем выполнять статистический анализ, визуализировать данные и автоматизировать обработку данных.
пакеты httr, jsonlite и dplyr
После установки R вам необходимо установить 3 дополнительных пакета: httr, jsonlite, и dplyr. Я включил это в пример кода.
httrПакет позволяет нам взаимодействовать с API и получать исходные данные с YouTube в формате JSON.
После jsonliteэтого пакет берет эти необработанные данные и преобразует их в читаемый формат.
Это dplyrуниверсальный пакет для обработки данных в R.
Потоковое видео в реальном времени не учитывает просмотры. В некоторых видео комментарии отключены. Поскольку видео на YouTube могут иметь разные свойства, некоторые результаты не согласуются с другими.
Вместо rbindэтого мы можем использовать bind_rowsin dplyrдля обработки данных привязки с несоответствующими столбцами.
Шаг 3: Примеры вызовов API Данных YouTube (необязательно)
На этом шаге мы рассмотрим некоторые примеры вызовов API, которые мы будем использовать для извлечения данных с YouTube.
Мы увидим, как выглядит вызов API, а также некоторые примеры результатов.
Основные условия данных YouTube
Давайте рассмотрим два канала YouTube – CS Dojo, канал по программированию и информатике, и Numberphile, математический канал.
CS Dojo: https://www.youtube.com/channel/UCxX9wt5FWQUAAz4UrysqK9A
Numberphile: https://www.youtube.com/user/numberphile
Обратите внимание, что каждый канал имеет разный формат URL-адреса, и мы можем идентифицировать канал по идентификатору канала или имени пользователя.
Совет: Каналы YouTube можно идентифицировать либо по идентификатору канала, либо по имени пользователя.
например, CS Dojo следует формату идентификатора канала. Таким образом, идентификатор канала UCxX9wt5FWQUAAz4UrysqK9A равен.
С другой стороны, файл Numberphile следует формату имени пользователя. В этом случае Имя пользователя является numberphile.
Для видео на YouTube каждый из них идентифицируется по идентификатору видео, и мы можем легко увидеть это в URL-адресе.
https://www.youtube.com/watch?v=bI5jpueiCWwВот, идентификатор видео bI5jpueiCWw.
Как Выглядит вызов API?
Вызов API данных YouTube имеет следующий формат:
https://www.googleapis.com/youtube/v3/{resource}?{parameters}Он {resource}сообщает нам, какую информацию мы хотим извлечь из YouTube. В примерах, приведенных в этом руководстве, мы извлекаем данные из трех основных ресурсов:
channelsчтобы получить информацию о каналеplaylistItemsчтобы просмотреть список всех видео, загруженных на канал или пользователемvideosдля получения подробной видеоинформации
Это {parameters}позволяет нам дополнительно настраивать результаты. Несколько параметров разделяются амперсандом (&). Обычно мы начинаем со следующих параметров:
key(требуется) для вашего ключа API YouTubeid,forUsername, илиplaylistIdдля уникального идентификатора каждой точки данныхpartдля извлечения конкретных точек данных
Получение информации о канале:
На основе идентификатора канала:
https://www.googleapis.com/youtube/v3/channels?key=**********&id=UCxX9wt5FWQUAAz4UrysqK9A&part=snippet,contentDetails,statisticsПараметры:
id=UCxX9wt5FWQUAAz4UrysqK9A(идентификатор канала CS Dojo)part=snippet,contentDetails,statistics
На основе имени пользователя:
https://www.googleapis.com/youtube/v3/channels?key=**********&forUsername=numberphile&part=snippet,contentDetails,statisticsПараметры:
forUsername=numberphile(имя пользователя Numberphile)part=snippet,contentDetails,statistics
Пример вывода для CS Dojo:
{
"kind": "youtube#channelListResponse",
"etag": "5FIor9Xof7m3UK8GnHryg5Jg-ig",
"pageInfo": {
"totalResults": 1,
"resultsPerPage": 1
},
"items": [
{
"kind": "youtube#channel",
"etag": "qL9berEsH5jF5LmNRTOzuXJYNHA",
"id": "UCxX9wt5FWQUAAz4UrysqK9A",
"snippet": {
"title": "CS Dojo",
"description": "Hi there! My name is YK, and I make videos mostly about programming and computer science here.\n\nIf you haven't yet, you should join our Discord, Facebook or Reddit community at csdojo.io/community!\n\nI also have a channel where I talk about other things. It's called Hey YK. You can find it on the right or on the \"Channels\" tab.\n\nYou can also find me @ykdojo on Twitter and Instagram :)\n\nHave a programming-related question? I might have already answered it on my FAQ page here: csdojo.io/faq (you can find this link either below or above, too)\n\nIf you can't find your question there, maybe try asking it on one of our communities here: csdojo.io/community\n\n\nBusiness email: https://www.csdojo.io/contact/\nLogo cred: Youdong Zhang",
"customUrl": "csdojo",
"publishedAt": "2016-02-26T01:49:30Z",
"thumbnails": {
"default": {
"url": "https://yt3.ggpht.com/a/AATXAJxJwY29yXENbgxRO0WxVMtiWyt65BT9iF2mNgWJ=s88-c-k-c0xffffffff-no-rj-mo",
"width": 88,
"height": 88
},
"medium": {
"url": "https://yt3.ggpht.com/a/AATXAJxJwY29yXENbgxRO0WxVMtiWyt65BT9iF2mNgWJ=s240-c-k-c0xffffffff-no-rj-mo",
"width": 240,
"height": 240
},
"high": {
"url": "https://yt3.ggpht.com/a/AATXAJxJwY29yXENbgxRO0WxVMtiWyt65BT9iF2mNgWJ=s800-c-k-c0xffffffff-no-rj-mo",
"width": 800,
"height": 800
}
},
"localized": {
"title": "CS Dojo",
"description": "Hi there! My name is YK, and I make videos mostly about programming and computer science here.\n\nIf you haven't yet, you should join our Discord, Facebook or Reddit community at csdojo.io/community!\n\nI also have a channel where I talk about other things. It's called Hey YK. You can find it on the right or on the \"Channels\" tab.\n\nYou can also find me @ykdojo on Twitter and Instagram :)\n\nHave a programming-related question? I might have already answered it on my FAQ page here: csdojo.io/faq (you can find this link either below or above, too)\n\nIf you can't find your question there, maybe try asking it on one of our communities here: csdojo.io/community\n\n\nBusiness email: https://www.csdojo.io/contact/\nLogo cred: Youdong Zhang"
},
"country": "CA"
},
"contentDetails": {
"relatedPlaylists": {
"likes": "",
"favorites": "",
"uploads": "UUxX9wt5FWQUAAz4UrysqK9A",
"watchHistory": "HL",
"watchLater": "WL"
}
},
"statistics": {
"viewCount": "52080104",
"commentCount": "0",
"subscriberCount": "1430000",
"hiddenSubscriberCount": false,
"videoCount": "90"
}
}
]
}Загружает идентификатор списка воспроизведения. Значение для items#contentDetails#relatedPlaylists#uploads-это “список воспроизведения”, содержащий все загруженные видео пользователем или channel.
In в этом примере uploads значение равно UUxX9wt5FWQUAAz4UrysqK9A, и мы будем использовать его в последующих примерах.
Получение информации о плейлисте:
Первоначальный вызов API:
https://www.googleapis.com/youtube/v3/playlistItems?key=**********&playlistId=UUxX9wt5FWQUAAz4UrysqK9A&part=snippet,contentDetails,status&maxResults=2Параметры:
id=UUxX9wt5FWQUAAz4UrysqK9A(идентификатор списка воспроизведения загрузок CS Dojo)part=snippet,contentDetails,statisticsmaxResults=2(показывать не более 2 видео одновременно)
Последующие страницы (через pageToken):
https://www.googleapis.com/youtube/v3/playlistId?key=**********&playlistId=UUxX9wt5FWQUAAz4UrysqK9A&part=snippet,contentDetails,status&maxResults=2&pageToken=CAIQAAПараметры:
id=UUxX9wt5FWQUAAz4UrysqK9A(идентификатор списка воспроизведения загрузок CS Dojo)part=snippet,contentDetails,statisticsmaxResults=2(показывать не более 2 видео одновременно)pageToken=CAIQAA(получение результатов в пакетах или “страницах”)
Пример вывода для CS Dojo:
{
"kind": "youtube#playlistItemListResponse",
"etag": "udxsDzE2VxvdihCnCMbQcXWW0w8",
"nextPageToken": "CAIQAA",
"items": [
{
"kind": "youtube#playlistItem",
"etag": "eM4VjwjWHWHjaSNE-Hw1qGAeDTE",
"id": "VVV4WDl3dDVGV1FVQUF6NFVyeXNxSzlBLjEtbF9VT0ZpMVh3",
"snippet": {
"publishedAt": "2020-07-25T05:04:05Z",
"channelId": "UCxX9wt5FWQUAAz4UrysqK9A",
"title": "Introduction to Trees (Data Structures & Algorithms #9)",
"description": "Here is my intro to the tree data structure!\n\nAnd here's another interesting tree problem: https://youtu.be/7HgsS8bRvjo\n\nYou can download my sample code in Python and Java here: https://www.csdojo.io/tree",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/1-l_UOFi1Xw/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/1-l_UOFi1Xw/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/1-l_UOFi1Xw/hqdefault.jpg",
"width": 480,
"height": 360
},
"standard": {
"url": "https://i.ytimg.com/vi/1-l_UOFi1Xw/sddefault.jpg",
"width": 640,
"height": 480
},
"maxres": {
"url": "https://i.ytimg.com/vi/1-l_UOFi1Xw/maxresdefault.jpg",
"width": 1280,
"height": 720
}
},
"channelTitle": "CS Dojo",
"playlistId": "UUxX9wt5FWQUAAz4UrysqK9A",
"position": 0,
"resourceId": {
"kind": "youtube#video",
"videoId": "1-l_UOFi1Xw"
}
},
"contentDetails": {
"videoId": "1-l_UOFi1Xw",
"videoPublishedAt": "2020-07-25T05:04:05Z"
},
"status": {
"privacyStatus": "public"
}
},
{
"kind": "youtube#playlistItem",
"etag": "wjH5CvGlE-K_Gquy_7L3fLs4XH8",
"id": "VVV4WDl3dDVGV1FVQUF6NFVyeXNxSzlBLmJJNWpwdWVpQ1d3",
"snippet": {
"publishedAt": "2020-05-30T01:44:22Z",
"channelId": "UCxX9wt5FWQUAAz4UrysqK9A",
"title": "Why and How I Used Vue.js for My Python/Django Web App (and why not React)",
"description": "Here’s why and how I used Vue.js for my Python/Django web app.\n\nYou can try using this website here: https://csqa.io/\nAnd here’s the article I used for setting up Django with React for my previous project: https://medium.com/uva-mobile-devhub/set-up-react-in-your-django-project-with-webpack-4fe1f8455396\n\nOther Relevant Resources:\nThe source code of this project: https://github.com/ykdojo/csqa\nDjango Rest Framework’s serializer library: https://www.django-rest-framework.org/api-guide/serializers/\nUsing Axios with Vue: https://vuejs.org/v2/cookbook/using-axios-to-consume-apis.html",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/bI5jpueiCWw/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/bI5jpueiCWw/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/bI5jpueiCWw/hqdefault.jpg",
"width": 480,
"height": 360
},
"standard": {
"url": "https://i.ytimg.com/vi/bI5jpueiCWw/sddefault.jpg",
"width": 640,
"height": 480
},
"maxres": {
"url": "https://i.ytimg.com/vi/bI5jpueiCWw/maxresdefault.jpg",
"width": 1280,
"height": 720
}
},
"channelTitle": "CS Dojo",
"playlistId": "UUxX9wt5FWQUAAz4UrysqK9A",
"position": 1,
"resourceId": {
"kind": "youtube#video",
"videoId": "bI5jpueiCWw"
}
},
"contentDetails": {
"videoId": "bI5jpueiCWw",
"videoPublishedAt": "2020-05-30T01:44:22Z"
},
"status": {
"privacyStatus": "public"
}
}
],
"pageInfo": {
"totalResults": 90,
"resultsPerPage": 2
}
}Получение видеоинформации:
На основе идентификатора видео:
https://www.googleapis.com/youtube/v3/videos?key=**********&id=bI5jpueiCWw&part=id,contentDetails,statisticsПараметры:
id=bI5jpueiCWw(идентификатор видео)part=id,contentDetails,statistics
Пример вывода для видео CS Dojo:
{
"kind": "youtube#videoListResponse",
"etag": "gFzSNw_4_LeqUG5vYUleZ3wCBU8",
"items": [
{
"kind": "youtube#video",
"etag": "2NLSBa1k4oDCopuEumzjtVGMFFM",
"id": "bI5jpueiCWw",
"contentDetails": {
"duration": "PT20M34S",
"dimension": "2d",
"definition": "hd",
"caption": "false",
"licensedContent": true,
"contentRating": {},
"projection": "rectangular"
},
"statistics": {
"viewCount": "79084",
"likeCount": "2075",
"dislikeCount": "52",
"favoriteCount": "0",
"commentCount": "349"
}
}
],
"pageInfo": {
"totalResults": 1,
"resultsPerPage": 1
}
}Шаг 4: Пример кода для извлечения данных YouTube в R
Вот пример, который мы можем использовать для извлечения данных из канала YouTube.
Во-первых, установите переменную ключа с помощью ключа API YouTube.
key <- "… add your YouTube API key here …"Далее я рекомендую настроить переменные, которые вы будете часто использовать на протяжении всего сценария.
channel_id <- "UCxX9wt5FWQUAAz4UrysqK9A" # CS Dojo Channel ID
user_id <- "numberphile" # Numberphile Username
base <- "https://www.googleapis.com/youtube/v3/"Установите свой рабочий каталог, если вы хотите сохранить выходные данные. Используйте косую черту вперед вместо обратной косой черты
setwd("C:/Output ")Загрузите и установите необходимые пакеты. Я рекомендую изменить repos в зависимости от того, где вы находитесь.
required_packages <- c("httr", "jsonlite", "here", "dplyr")
for(i in required_packages) {
if(!require(i, character.only = T)) {
# if package is not existing, install then load the package
install.packages(i, dependencies = T, repos = "http://cran.us.r-project.org")
# install.packages(i, dependencies = T, repos = "https://cran.stat.upd.edu.ph/")
require(i, character.only = T)
}
}Давайте извлечем информацию о канале для CS Dojo с помощью httr пакета.
# Construct the API call
api_params <-
paste(paste0("key=", key),
paste0("id=", channel_id),
"part=snippet,contentDetails,statistics",
sep = "&")
api_call <- paste0(base, "channels", "?", api_params)
api_result <- GET(api_call)
json_result <- content(api_result, "text", encoding="UTF-8")Это json_result необработанные данные в формате JSON. Давайте воспользуемся jsonlite пакетом и отформатируем эти необработанные данные в фрейм данных.
# Process the raw data into a data frame
channel.json <- fromJSON(json_result, flatten = T)
channel.df <- as.data.frame(channel.json)Некоторые важные столбцы во фрейме channel.df данных:
id
snippet.title
snippet.description
snippet.customUrl
snippet.publishedAt
snippet.country
contentDetails.relatedPlaylists.uploads
statistics.viewCount
statistics.commentCount
statistics.subscriberCount
statistics.videoCountДавайте использовать идентификатор contentDetails.relatedPlaylists.uploads нашего плейлиста в качестве идентификатора.
playlist_id <- channel.df$contentDetails.relatedPlaylists.uploadsТеперь, поскольку плейлист может содержать большое количество видео, нам нужно разбить их на “страницы”. Мы извлекаем по 50 видео за раз, пока API не сообщит нам, что мы достигли последней страницы.
# temporary variables
nextPageToken <- ""
upload.df <- NULL
pageInfo <- NULL
# Loop through the playlist while there is still a next page
while (!is.null(nextPageToken)) {
# Construct the API call
api_params <-
paste(paste0("key=", key),
paste0("playlistId=", playlist_id),
"part=snippet,contentDetails,status",
"maxResults=50",
sep = "&")
# Add the page token for page 2 onwards
if (nextPageToken != "") {
api_params <- paste0(api_params,
"&pageToken=",nextPageToken)
}
api_call <- paste0(base, "playlistItems", "?", api_params)
api_result <- GET(api_call)
json_result <- content(api_result, "text", encoding="UTF-8")
upload.json <- fromJSON(json_result, flatten = T)
nextPageToken <- upload.json$nextPageToken
pageInfo <- upload.json$pageInfo
curr.df <- as.data.frame(upload.json$items)
if (is.null(upload.df)) {
upload.df <- curr.df
} else {
upload.df <- bind_rows(upload.df, curr.df)
}
}upload.df Содержит 90 строк, соответствующих 90 видео, загруженным в канале CS Dojo.
На этом этапе каждая строка во фрейме данных upload.df будет содержать основную информацию о видео, такую как идентификатор видео, Название, Описаниеи Дата загрузки.
Если нам нужна статистика видео, такая как количество просмотров, лайков и комментариев, нам нужно выполнить третий набор вызовов API к videos ресурсу.
video.df<- NULL
# Loop through all uploaded videos
for (i in 1:nrow(upload.df)) {
# Construct the API call
video_id <- upload.df$contentDetails.videoId[i]
api_params <-
paste(paste0("key=", key),
paste0("id=", video_id),
"part=id,statistics,contentDetails",
sep = "&")
api_call <- paste0(base, "videos", "?", api_params)
api_result <- GET(api_call)
json_result <- content(api_result, "text", encoding="UTF-8")
video.json <- fromJSON(json_result, flatten = T)
curr.df <- as.data.frame(video.json$items)
if (is.null(video.df)) {
video.df <- curr.df
} else {
video.df <- bind_rows(video.df, curr.df)
}
} Обратите внимание, что я использовал цикл, а не векторизованный подход.
Наконец, мы можем объединить информацию в единый фрейм данных, называемый video_final.df.
# Combine all video data frames
video.df$contentDetails.videoId <- video.df$id
video_final.df <- merge(x = upload.df,
y = video.df,
by = "contentDetails.videoId")Вы можете дополнительно обработать свои данные, выбрав определенные столбцы или расположив их в определенном порядке.
Наконец, вы можете записать свой фрейм данных в файл. Я предпочитаю сохранять два файла – один для сведений о канале, а другой для сведений о загруженном видео.
write.csv(x = channel.df,
row.names = F,
file = "CS_Dojo_Channel.csv")
write.csv(x = video_final.df,
row.names = F,
file = "CS_Dojo_Uploads.csv")Является ли API данных YouTube бесплатным?
API является бесплатным для первых 2 миллионов единиц вызовов API в месяц. Это намного больше, чем вам понадобится, если вы анализируете несколько каналов одновременно.
Канал YouTube с 200 загруженными видео выполняет более 600 вызовов APIдля всех данных, которые мы извлекли в примерах.
За вызовы API свыше 2 миллионовс вас будет взиматься плата в размере 3 долларов США за 1 миллион вызовов API.
Если вы совершаете более 1 миллиарда вызовов API в месяц, это дополнительно снижается до 1,50 доллара за миллион вызовов API.
Альтернативы использованию R
Как мы видели на шаге 3, пока вы можете подготовить конечную точку API, вы можете извлекать данные с помощью любого инструмента, который может отправлять HTTP-запросы (GET).
Я использую Postman для быстрого и простого тестирования, а затем завершаю свои сценарии в R для поддержки автоматизации.
Вы также можете сделать это на других языках программирования, таких как Java, JavaScript или Python.
Помимо httrjsonliteпакетов и, вы также можете использовать другие существующие пакеты.
tuber Пакет специализируется на анализе данных YouTube, но использует OAuth вместо ключа API.
Вывод
Мы смогли автоматизировать извлечение данных в YouTube с помощью R и API данных YouTube.
