
Сегодня организации собирают данные рекордными темпами. От измерений датчиков до поведения потребителей объем данных растет экспоненциально, и вместе с этим растет потребность в инструментах, ориентированных на большие данные и аналитику. Такие инструменты чрезвычайно полезны, например, с базами данных Google Cloud .
Хорошие инструменты и решения, которые позволяют нам хранить и быстро анализировать большие объемы данных, имеют огромное значение в повседневной жизни, обеспечивая максимальную отдачу от наших наборов данных и позволяя принимать решения на основе данных. Google Cloud предлагает эту возможность в Google Cloud BigQuery.
В этом посте более подробно рассматривается эта утилита для работы с большими данными из Google Cloud и способы ее использования.
Чтобы перейти к инструкциям, используйте эту ссылку How to Use Google BigQuery
Что такое Google BigQuery?
BigQuery – это полностью управляемое бессерверное решение для хранилища данных, доступное на платформе Google Cloud Platform, которое дает любому пользователю возможность анализировать терабайты данных за считанные секунды.
Архитектура Google BigQuery основана на Dremel, распределенной системе, созданной Google для запросов к большим наборам данных, однако это лишь малая часть того, что происходит с BigQuery. Dremel разделяет выполнение запроса на слоты, обеспечивая справедливость, когда несколько пользователей запрашивают данные одновременно. Под капотом Dremel полагается на Jupiter, внутреннюю сеть центра обработки данных Google, для доступа к хранилищу данных в распределенной файловой системе под кодовым названием Colossus. Colossus занимается репликацией данных, восстановлением и управлением распространением.
BigQuery хранит данные в формате столбцов, обеспечивая высокую степень сжатия и скорость сканирования. Однако вы также можете использовать BigQuery с данными, хранящимися в других облачных сервисах Google, таких как BigTable, Cloud Storage, Cloud SQL и Google Drive.
Благодаря этой архитектуре, предназначенной для работы с большими данными, BigQuery лучше всего работает при наличии нескольких петабайт данных для анализа. Варианты использования, наиболее подходящие для BigQuery, — это те, в которых людям необходимо выполнять интерактивные специальные запросы к наборам данных, доступным только для чтения. Как правило, BigQuery используется в конце конвейера ETL больших данных поверх обработанных данных или в сценариях, когда сложные аналитические запросы к реляционной базе данных занимают несколько секунд. Благодаря встроенному кешу BigQuery отлично работает в тех случаях, когда данные меняются нечасто. Кроме того, в случаях, когда наборы данных довольно малы, использование BigQuery не приносит особой пользы, поскольку простой запрос занимает до нескольких секунд. Таким образом, ее не следует использовать в качестве обычной базы данных OLTP (онлайн-обработка транзакций). BigQuery действительно предназначен и подходит для БОЛЬШИХ данных и аналитики.
Будучи полностью управляемым сервисом, он работает «из коробки» без необходимости установки, настройки и эксплуатации какой-либо инфраструктуры. С клиентов просто взимается плата в зависимости от запросов, которые они делают, и объема сохраненных данных. Однако у «черного ящика» есть свои недостатки, поскольку у вас очень мало контроля над тем, где и как хранятся и обрабатываются ваши данные.
Ключевым ограничением и недостатком является то, что BigQuery работает только с данными, хранящимися в Google Cloud, и использует собственные службы хранения. Поэтому не рекомендуется использовать его в качестве основного места хранения данных, поскольку это ограничивает будущие сценарии архитектуры. Тогда предпочтительнее хранить необработанный набор данных в другом месте и использовать копию в BigQuery для аналитики.
Как использовать Google BigQuery
BigQuery доступен в Google Cloud Platform. Клиенты GCP могут легко получить доступ к сервису из привычной консоли веб-интерфейса. Помимо консоли пользовательского интерфейса, доступ к API Google BigQuery можно получить с помощью существующих GCP SDK и инструментов CLI.
Начать работу с Google Cloud BigQuery довольно просто и понятно. Вы можете очень быстро приступить к работе, используя любой набор данных в распространенном формате, таком как CSV, Parquet, ORC, Avro или JSON. Если у вас нет данных для использования в Google BigQuery, наборы данных находятся в свободном доступе для изучения и использования в общедоступных наборах данных Google Cloud .
Одним из примеров общедоступного набора данных являются данные о коронавирусе на портале открытых данных Европейского союза . Он содержит данные о случаях COVID-19 по всему миру и может использоваться бесплатно. Ниже мы расскажем вам, как изучить и проанализировать этот набор данных с помощью Google BigQuery.
Шаг 1. Загрузите набор данных на свой компьютер.
Для начала загрузите последнюю версию набора данных (в формате CSV) на локальный компьютер.
Шаг 2. Загрузка и сохранение набора данных в Google BigQuery
1. В облачной платформе Google перейдите к консоли Google BigQuery в разделе «Большие данные».
2. Найдите кнопку «СОЗДАТЬ НАБОР ДАННЫХ» на правой боковой панели и запустите процесс создания. Дайте набору данных уникальный идентификатор и выберите географическое положение для хранения и обработки данных. Сохраните его с помощью кнопки внизу панели.
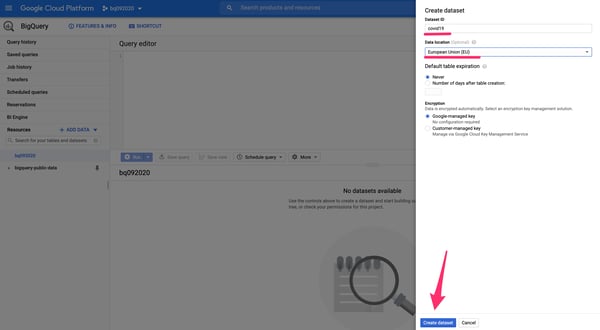 Панель создания базы данных нового набора данных BigQuery.
Панель создания базы данных нового набора данных BigQuery.
3. Выберите только что созданный набор данных и нажмите кнопку CREATE TABLE. Используйте Upload в качестве исходного метода, CSV в качестве формата файла и выберите локальный файл набора данных на своем компьютере. Дайте ей имя таблицы (например, world_cases) и выберите для схемы параметр Auto Detect. Сохраните его с помощью кнопки внизу панели.
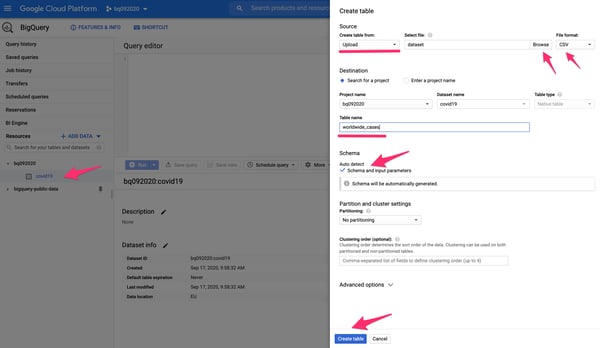 Панель создания таблиц нового набора данных BigQuery.
Панель создания таблиц нового набора данных BigQuery.
Шаг 3. Использование BigQuery для запроса данных, хранящихся в Google BigQuery
Загрузив и сохранив набор данных в BigQuery, вы сможете сразу начать запрашивать данные с помощью стандартного SQL.
1. В панели попробуйте выполнить простой запрос, например SELECT * FROM `bq092020.covid19.worldwide_cases` LIMIT 1000 , чтобы получить до тысячи строк.
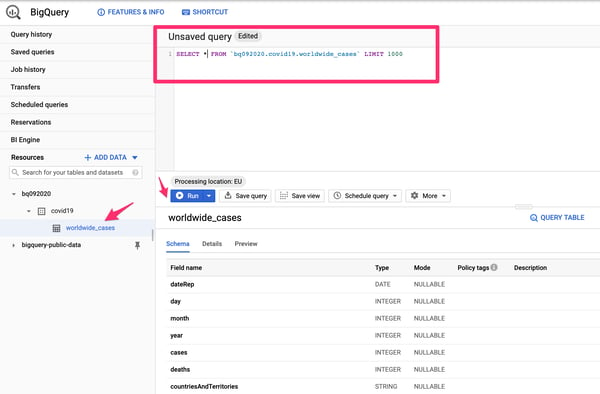 Простой запрос с использованием интерфейса Google BigQuery.
Простой запрос с использованием интерфейса Google BigQuery.
2. BigQuery Analytics довольно мощный инструмент. Интерфейс дает доступ к полноценным возможностям SQL, поэтому вы можете использовать более сложные запросы, такие как ВЫБЕРИТЕ страны и территории, сумма(случаи) КАК N_Случаев, сумма(смертей) КАК N_Смертей, подсчет(*) КАК N_Рядов
ИЗ `bq092020.covid19. world_cases`
ГРУППА ПО странам
и территориям LIMIT 1000
3. Выполнение приведенного выше запроса предоставит сводные результаты количества случаев и смертей по стране/территории.
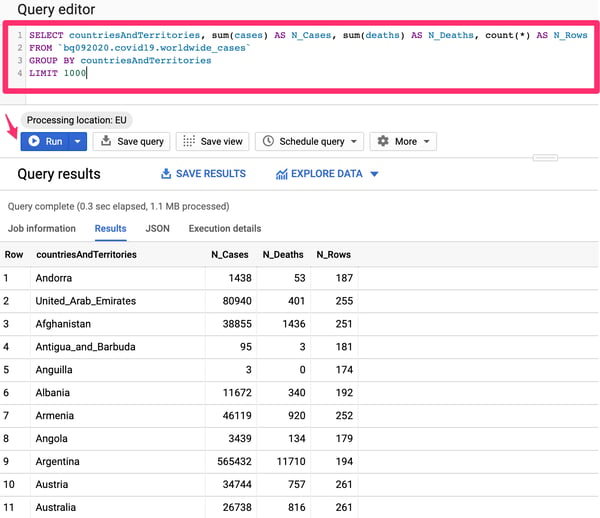 Агрегированные результаты запроса с использованием интерфейса Google BigQuery.
Агрегированные результаты запроса с использованием интерфейса Google BigQuery.
Шаг 4. Добавление набора данных в облачное хранилище Google
Поскольку Google BigQuery поддерживает некоторые внешние источники данных, мы можем добиться аналогичных результатов и возможностей, используя Google Cloud Storage в качестве хранилища данных для файла набора данных.
Создать новую корзину Google Cloud Storage и загрузить файл набора данных можно довольно просто. Если вы еще этого не сделали, вы можете узнать, как создать ведро здесь .
Шаг 5. Использование BigQuery с набором данных в Google Cloud Storage
1. Создайте новую таблицу в своем наборе данных BigQuery и выберите Google Cloud Storage в качестве источника. Заполните имя корзины GCS и местоположение файла, используя CSV в качестве формата. Дайте ей имя, отличное от имени предыдущей созданной таблицы (например, world_cases_in_bucket).
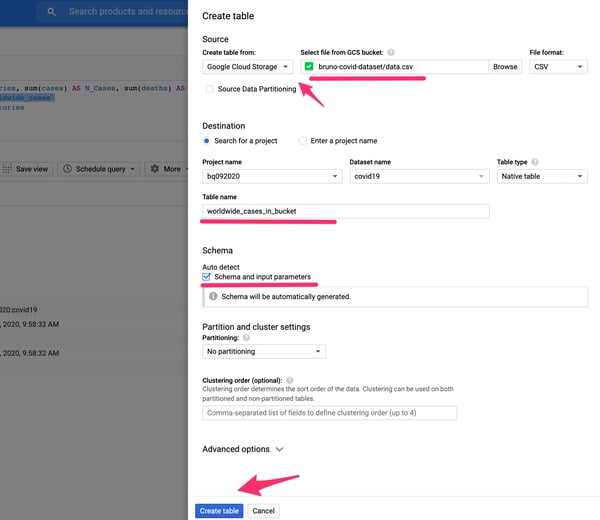 Создание таблицы из внешнего источника данных в Google BigQuery
Создание таблицы из внешнего источника данных в Google BigQuery
2. Вновь созданная таблица сразу появится в интерфейсе. Данные можно запрашивать точно так же, как и любые другие данные, хранящиеся в BigQuery. Чтобы проверить это, попробуйте использовать тот же запрос агрегации, просто обновив предложение FROM новым именем таблицы.
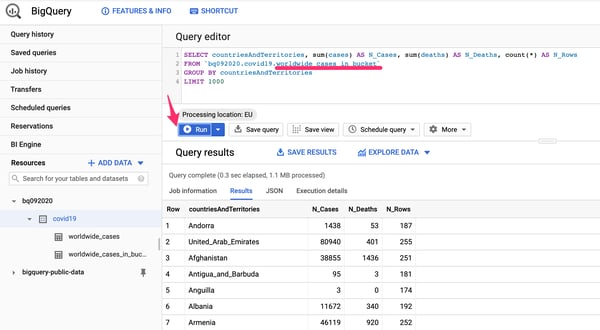 Использование BigQuery для запроса данных, хранящихся во внешнем источнике данных.
Использование BigQuery для запроса данных, хранящихся во внешнем источнике данных.
Заключение
Как вы только что видели, BigQuery невероятно эффективен, позволяя исследовать и анализировать данные с нуля без особых усилий. В мире, где сбор данных растет с поразительной скоростью, такие инструменты, как BigQuery, помогают создавать ценность из данных.
Однако, несмотря на свои уникальные преимущества и мощные функции, BigQuery не является панацеей. Не рекомендуется использовать его для данных, которые меняются слишком часто, и из-за того, что его место хранения привязано к собственным службам Google, и ограничений обработки лучше не использовать его в качестве основного хранилища данных.
Для клиентов, желающих хранить большие объемы данных, Cloud Volumes ONTAP , платформа управления данными от NetApp, является отличным вариантом. Доступный в AWS, Google Cloud и Azure, он позволяет клиентам сохранять открытыми варианты того, как и где их данные хранятся и обрабатываются. Cloud Volumes ONTAP идеально подходит для решений для работы с большими данными, предоставляя клиентам расширенные функции, такие как экономия средств, эффективность хранения, клонирование, многоуровневое хранение данных и защита, а также помогает сократить расходы на высокопроизводительное хранилище в некоторых случаях на 70 %.
